The Dataverse Project is an open source web application to share, preserve, cite, explore, and analyze research data. It facilitates making data available to others, and allows you to replicate others’ work more easily. Researchers, journals, data authors, publishers, data distributors, and affiliated institutions all receive academic credit and web visibility.
Taken from Dataverse Project website
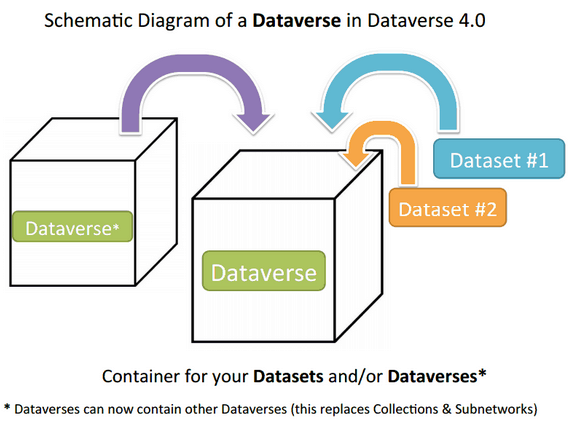
A Dataverse repository is the software installation, which then hosts multiple virtual archives called Dataverse collections. Each Dataverse collection contains datasets, and each dataset contains descriptive metadata and data files (including documentation and code that accompany the data). As an organizing method, Dataverse collections may also contain other Dataverse collections.
A dataverse is a container for datasets (research data, code, documentation, and metadata) and other dataverses, which can be setup for individual researchers, departments, journals and organizations. Dataverses are like folders on your computer – they allow to store and search data with ease.
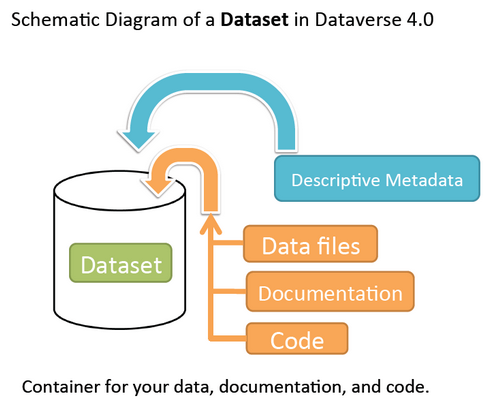
Dataset
A dataset in Dataverse is a container for your data, documentation, code, and the metadata describing this Dataset. To put it in simple terms: one dataset is a single project with all additional information about it.